Your Runbooks Are Already Skills. You Just Haven't Shipped Them.
Every ops team we've worked with has thousands of pages of runbooks. Some are good. Most are stale. Almost none of them get touched at 3am when the pager fires.
The irony is that the AI-executable version of your operational knowledge has been sitting in Confluence all along. You just haven't packaged it. The same Skills pattern Anthropic shipped for coding assistants (discoverable manifest, progressive disclosure, bundled execution context) is nearly identical to what a well-structured runbook already is. The gap is smaller than it looks, and closing it is the fastest path to shipping credible AI-augmented operations.
This is the follow-up to Stop Cramming Policies Into Your System Prompt, which made the case for Skills in business applications. This piece is for the teams running the infrastructure: SRE, DevOps, platform, security operations. The fit is tighter there, and the payoff is faster.
A runbook is 90% of a Skill
Pull any half-decent incident runbook off the shelf and you'll find roughly the same ingredients:
- A trigger condition ("Use this when PostgreSQL replication lag exceeds 5 minutes")
- A step-by-step procedure, often with command blocks
- References to dashboards, related systems, architecture diagrams
- An escalation ladder (who to page when the procedure doesn't resolve it)
- Templates for incident-channel announcements, status-page copy, post-mortem scaffolding
Now look at the structure of an Agent Skill:
- A manifest (
SKILL.md) with name, description, and trigger conditions - A body — the procedure in natural language
- References, loaded on demand
- Scripts the agent can run with scoped permissions
- Templates the agent fills in
The mapping is almost one-to-one. Your runbooks aren't waiting to be written. They're waiting to be packaged.
The 10% gap
A handful of things a runbook doesn't give you that a Skill does:
- Discoverability. A runbook in Confluence is discoverable by humans who know the page title. A Skill is discoverable by an agent scanning a registry of machine-readable descriptions. Same information, very different access patterns.
- Progressive disclosure. A runbook loads as one big page. A Skill loads metadata always, the body when the match is confirmed, and deep references only when the agent reaches for them. That matters because the agent's context window is finite, and an incident often touches several runbooks. You want the right fragments in context, not all of them at once.
- Executable artifacts. A runbook describes the command ("run
kubectl rollout undo deployment/api"). A Skill ships the command, with parameters, in a script the agent can actually execute inside a sandbox with scoped credentials. The difference between documentation and automation. - Versioning and audit. Most runbooks live in a wiki with thin revision history and no way to answer "which version of this runbook was used for that incident?" Skills are versioned, signed, and every invocation leaves an audit trail. When the incident review asks how the decision was made, you have an answer.
- Evolution discipline. Runbooks drift. Procedures change, people leave, new failure modes appear. In most orgs, updating a runbook after an incident is an optional TODO that doesn't happen. A Skills registry makes the post-mortem feedback loop a first-class artifact: the post-mortem produces a Skill update.
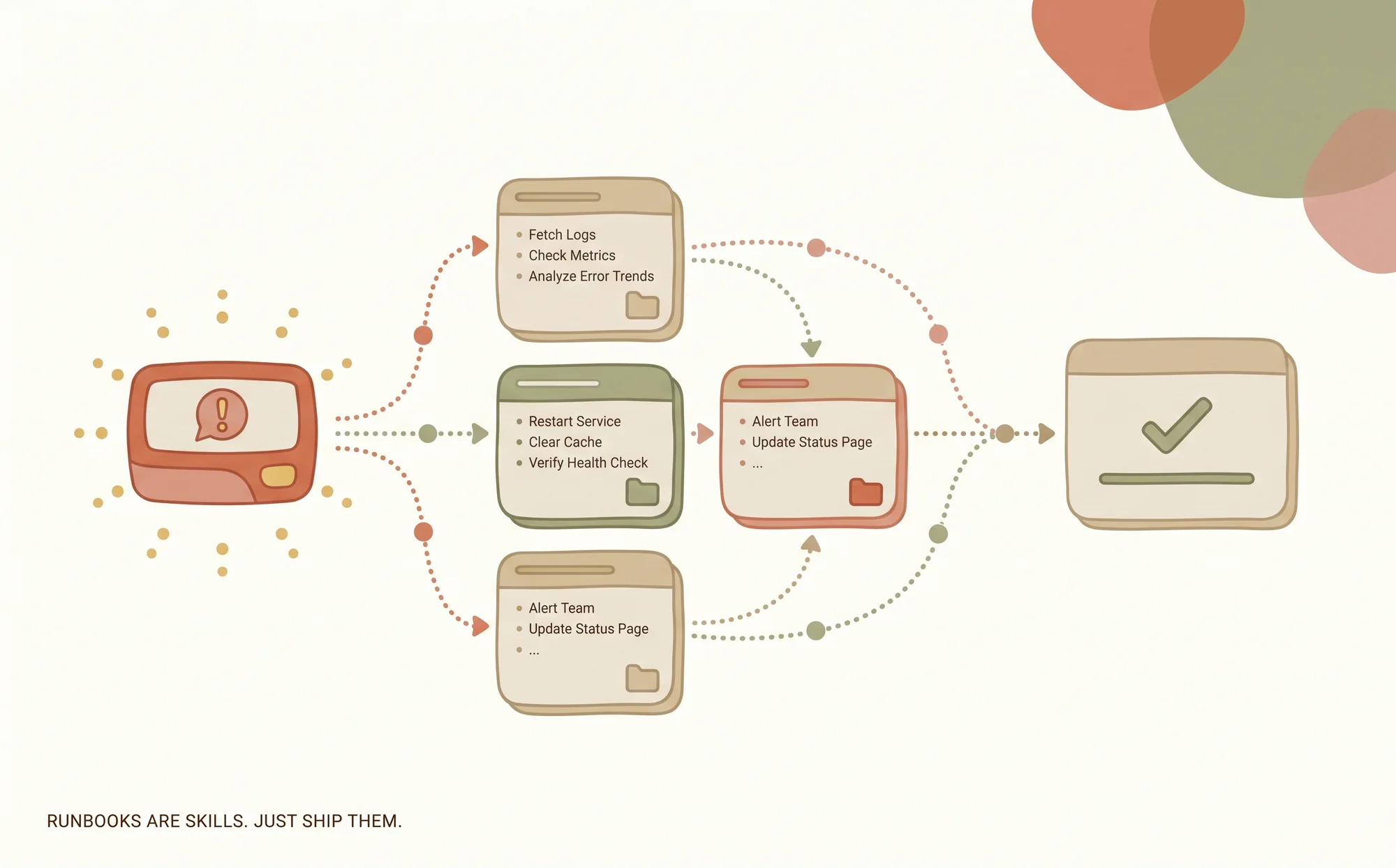
What it looks like: a database failover Skill
Pick a common ops runbook, "Primary Postgres is down, failover to replica." Here's the Skill version:
postgres-primary-failover/
├── SKILL.md # "Use when primary PostgreSQL is unreachable for >2m"
├── references/
│ ├── cluster-topology.md
│ ├── replication-lag-thresholds.md
│ └── rollback-if-split-brain.md
├── scripts/
│ ├── check_cluster_health.sh
│ ├── promote_replica.sh # requires approval token
│ └── update_dns_record.py
├── templates/
│ ├── incident_announcement.md
│ ├── status_page_update.md
│ └── post_mortem_scaffold.md
└── policies/
├── approval_matrix.md # who can authorize promotion
└── blast_radius.md # what the agent is NOT allowed to doAn on-call agent (LLM-powered or human) is paged, pulls this Skill, and walks through the procedure. The promotion script requires an approval token the agent can't mint on its own. If something goes wrong, the audit log shows exactly which Skill version ran, which parameters were used, and which approver authorized the promotion. That's a post-mortem artifact you don't have to reconstruct after the fact.
Why this matters more for ops than for business apps
The Skills argument is stronger in operations than in CRM or ERP. Four reasons.
The prior art is already there
Ops teams have been writing runbooks for fifteen years. Business-app teams rarely have the equivalent. Starting from "we already have a runbook library" is a fundamentally different starting position than starting from zero.
Consistency saves sleep
In CRM, inconsistent renewal handling costs a little margin. In ops, inconsistent failover handling costs a three-hour outage. The upside of Skills compounds fast when the cost of variance is measured in downtime.
Auditability is non-negotiable
Post-incident review is already table stakes in mature ops organizations. The question "how did we decide?" already has a framework (the incident review). Skills just give that framework a better answer.
Blast radius is real
An AI agent executing DROP TABLE isn't a theoretical concern. A Skills registry with per-Skill blast-radius policy and scoped execution is the only responsible way to give agents write-access to production. If you wouldn't let a human engineer run that command without approval, you shouldn't let the agent do it either. The Skill is where that policy lives.
What you need to build
Most of the platform shape matches the business-app case, but ops-specific concerns dominate:
- A Skill registry keyed to services. A per-service directory of Skills (
postgres-primary-cluster,api-gateway,payment-service) mirrors the mental model on-call engineers already use. Discovery lines up with how humans think about the system. - Integration with paging and alerting. Pagerduty or Opsgenie webhooks should resolve to candidate Skills based on alert class. Discovery happens inside the incident channel, not as a separate step after the page.
- Execution sandbox with blast-radius controls. Each Skill declares what it's allowed to touch.
kubectlagainst staging is not the same askubectlagainst production. Credentials are scoped per Skill, per environment, per invocation. Never the agent's god-mode service account. - Approval gates for destructive operations. Any Skill that can delete, promote, or failover requires human approval before execution. The agent runs the diagnostic steps, pauses, and asks. Approval tokens are signed, scoped, single-use.
- Audit log tied to incidents. Every Skill invocation is linked to an incident ID. Post-mortems read the audit log to reconstruct what happened: who approved, what ran, what changed.
- Post-mortem → Skill update pipeline. When a post-mortem surfaces "the runbook was wrong on step 4," the correction flows back into the Skill as a signed change with a link to the incident. Skills improve continuously, not episodically.
The migration path
Teams that try to Skills-ify everything at once fail. Teams that start with a narrow slice succeed. A reasonable staged approach:
- Pick the top 5–10 runbooks by incident frequency. Your paging metrics already tell you which ones. Start where the volume is.
- Convert each to Skill format. Pure repackaging at first. No execution, just structure. The goal is a discoverable, versioned manifest. Nothing automated yet.
- Dry-run execution. The agent walks through the Skill against a real alert but takes no action. It produces a proposed set of commands a human approves. This is where gaps in the runbook surface ("wait, step 4 assumes the pod is already drained, but we don't drain first anymore").
- Supervised execution. The agent executes read-only diagnostic steps. Destructive steps still require approval. Most of the value lives here. The agent is doing 80% of the work a senior SRE would do before the senior SRE is even awake.
- Narrow autonomous classes. For tightly scoped Skills with small blast radius (rotating a credential, restarting a stateless pod, scaling a deployment group), the agent can run autonomously with full audit. Broadly scoped destructive actions stay supervised indefinitely.
Most teams never need to progress past step 4 to capture 80% of the value. The value isn't "AI runs our ops." It's "our ops are executable, auditable, and consistent."
The bigger picture
Runbook discipline has always been a signal of ops maturity. Teams that write runbooks and keep them current run better than teams that don't. The Skills era doesn't change that. It rewards it.
The teams that already take runbooks seriously are the ones closest to shipping AI-augmented operations, because the hard work (capturing procedural knowledge) is already done. The gap is packaging and governance. For everyone else, the Skills pattern is a forcing function. If you want AI to help run production, you first have to write down how production is run.
Skills aren't a new tool to buy. They're the artifact your best SREs have already been producing for years, now legible to the rest of the stack.
At Atharvix, we spend time on both sides of this architecture: the business-app Skills layer and the operations Skills layer. They're the same pattern serving different audiences. If you have a runbook library that's 80% good and 100% stale, we'd love to talk about what it takes to turn it into infrastructure. Get in touch.